如今的软件开发是在遍地敏捷,人人讲唯快不破的时代,哪有人有时间思考代码质量,设计的质量? 哪个又不是从一堆代码中杀出血路来实现还有一个功能?一个产品都存活不了几年,何必考虑什么可维护性?
我们追求进度的时候,总是要牺牲些东西。或是破坏了一些东西等着后面补。
这就是技术债!
管理不好,债台高筑,即使不破产,也是要拆东墙。补西墙的玩平衡。
现实是残酷的。但不影响我们抬头看看这个世界。
技术债务
技术债务(Technical Debt)这个词,我最早是从InfoQ关于Uber的一个訪谈中了解到的,正好也在思考持续重构的问题,发现它是推动持续重构的有效工具。
所以花了点时间做些学习,在这里做个分享,主要来自这篇文章的学习,有时间的直接看原文就好了:
关于技术债务。并非新名词,就不考据它的历史了。事实上非常多团队都有相似的工具,比方:问题记录。优化点,TODO List等等。可是一般是比較松散。大杂烩式的,不系统。
我总结之前没有管理好有两点:
- 范围太大 在一篇IEEE 2012一期的文章(Technical Debt:From metaphor to Theory and Practice)里也强调了一个重要的观点,Technical Debt不要同需求和Bug搞在一起, 应当聚焦在对未来有负作用的设计和实现,通常都是无法直接感知的。比方性能优化到多少多少,这不是技术债务。
回忆曾经做的优化点,太过于聚焦于功能,更像为了未来开发工作安排的參考。
- 缺少到位的管理 假设一件事仅仅是追求锦上添花。它自然就会被排到低优先级。然后。太天真了,事实上没有然后了。
对策就不说了,这是一个管理问题,见仁见智。假设没有意识。或者正如开头说的。假设认为没有必要的话,确实不须要做什么,由于大家都几乎相同。
假设想要做。我们怎样定义和评估技术债务呢? 向率先者学习!
FireFox和Chromium都算是比較大的开源项目了。各自是280万行和470万行的规模。看看他们的总结就是非常好的学习了。核心是以量化的方式评价和管理代码,工具是基于。(事实上以发现&记录的方式也非常好,这里仅仅是作为參考的方式。
)
技术债务的量化 (即代码质量的评价)
主要来自
。
要优化,就要先定义问题和评价的标准。
下面代码质量评价的维度:- LOC (代码行数) 代表了代码的规模。能够用这个: 代码量越大。系统的复杂越高,可是相对的Bug率反而越低。
评估的对象没有说明。显然是针对设计良好的系统。
假设架构设计良好。而且大家都遵守,这样新增的功能都会集中以组件的形式实现。并不会改变接口,这是Bug没有扩散的原因。
- 圈复杂度 不多说了。不知道的看这里:。假设要严谨的定义,以软件project类书中的定义为准。
- 一阶密度 (First-Order Density) 用于评估文件间的直接依赖程度,由于是直接依赖。所以是一阶。里面仅仅有A和B的关系。相应的工具是DSM, Design Structure Matrix。Github上能够找到一个工具,我没有试过。
- 变更成本 (Propagation Cost) 评估任意的改一个文件,平均会影响到多少文件。
它能够反应直接依赖的一阶关系,也能够随着间接依赖层次上升的高阶关系。
这也是一个衡量架构设计的重要指标。欢迎推荐相关的工具。 - 核心代码大小 (Core size) 所以核心代码,是从依赖关系上定义的。假设文件间有着环形依赖形式的高度依赖就是所谓的核心代码。非常多研究已经证明,这类的代码量越小,Bug就越少。
工具
代码静态分析工具
LOC, 圈复杂度,以及依赖关系这些都easy通过一个静态分析工具来获得。
比方两者的代码量变化: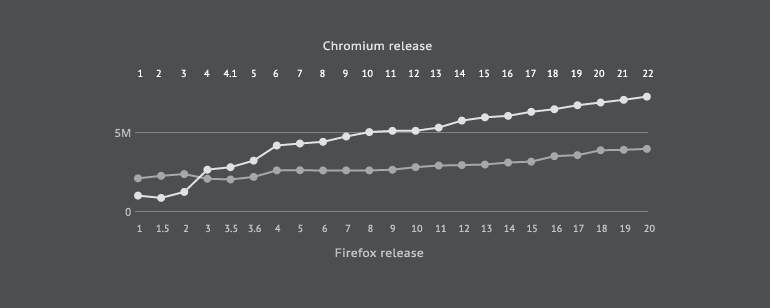 两者的圈复杂度:
两者的圈复杂度: 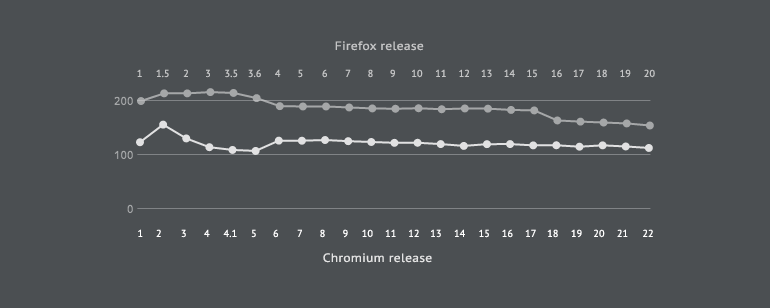
网络化处理 (Network Multiplication)
通过网络化处理。能够得出变更成本,一阶密度,核心代码大小的数据。 下图为Firefox&Chromium变更成本的比較: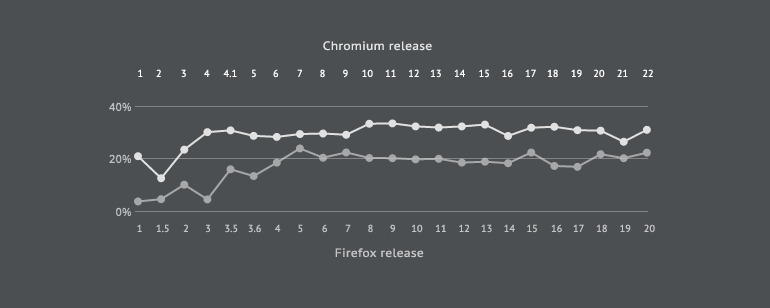 下图则是Core size的对照:
下图则是Core size的对照: 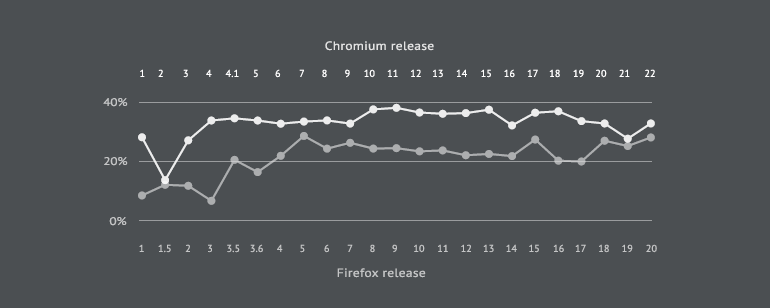
- DSM工具。 DSM事实上非常easy。就是描写叙述系统中各个元素的有无关系。横轴和纵轴都是系统各个元素,假设i,j有关联。则矩阵中(i,j)就是为true,或者作个标记。
下图就是作者提供的一张Firefox 16的DSM: 左側为直接依赖。右側为间接依赖。
左側为直接依赖。右側为间接依赖。
更具体的内容,參考:
数据能够在这里体验: 完整的文档在Github上: 其大致的处理流程例如以下图: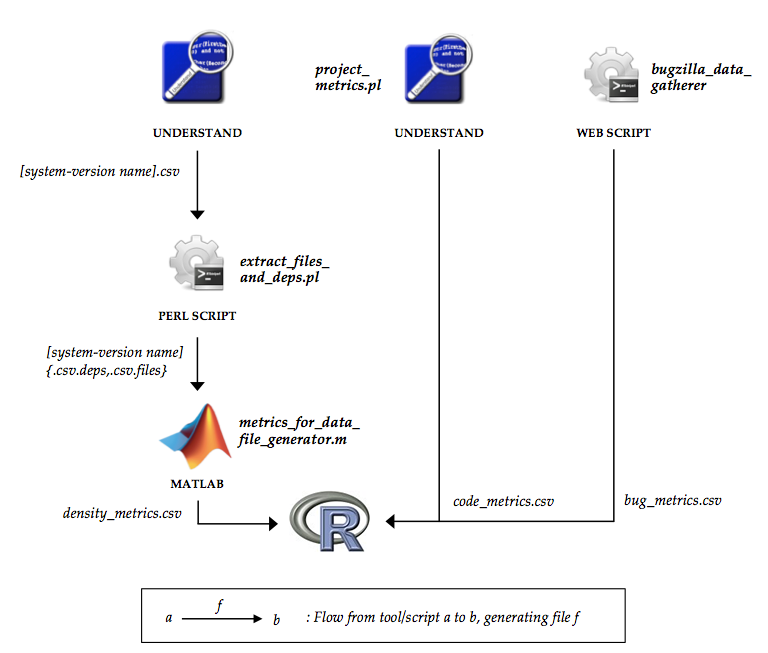
总结
技术债务的定义仅仅是參考。更重要的还是意识和运行。
有了基本概念和意愿。运行的工具就非常灵活,全然一个技术管理的行为。
关注微信公众号交流:

转载请注明出处: